# Define the dual mesh
dmesh <- book.mesh.dual(mesh)
w <- sapply(1:length(dmesh), function(i) {
if (gIntersects(dmesh[i, ], domainSP))
return(gArea(gIntersection(dmesh[i, ], domainSP)))
else return(0)
})
# augment data and compute weights
y.pp <- rep(0:1, c(nv, n))
e.pp <- c(w, rep(0, n))
# define projection matrix and stack
imat <- Diagonal(nv, rep(1, nv))
lmat <- inla.spde.make.A(mesh, xy)
A.pp <- rbind(imat, lmat)
stk.pp <- inla.stack(
data = list(y = y.pp, e = e.pp),
A = list(1, A.pp),
effects = list(list(b0 = rep(1, nv + n)),
list(i = 1:nv)),
tag = 'pp')
# run the inla function
pp.res <- inla(
y ~ 0 + b0 + f(i, model = spde),
family = 'poisson',
data = inla.stack.data(stk.pp),
control.predictor = list(A = inla.stack.A(stk.pp)),
E = inla.stack.data(stk.pp)$e)Extending Lee–Carter Models with inlabru: Spatio-Temporal Applications in Health and Mortality
Sara Martino 
Dept. of Mathematical Science, NTNU
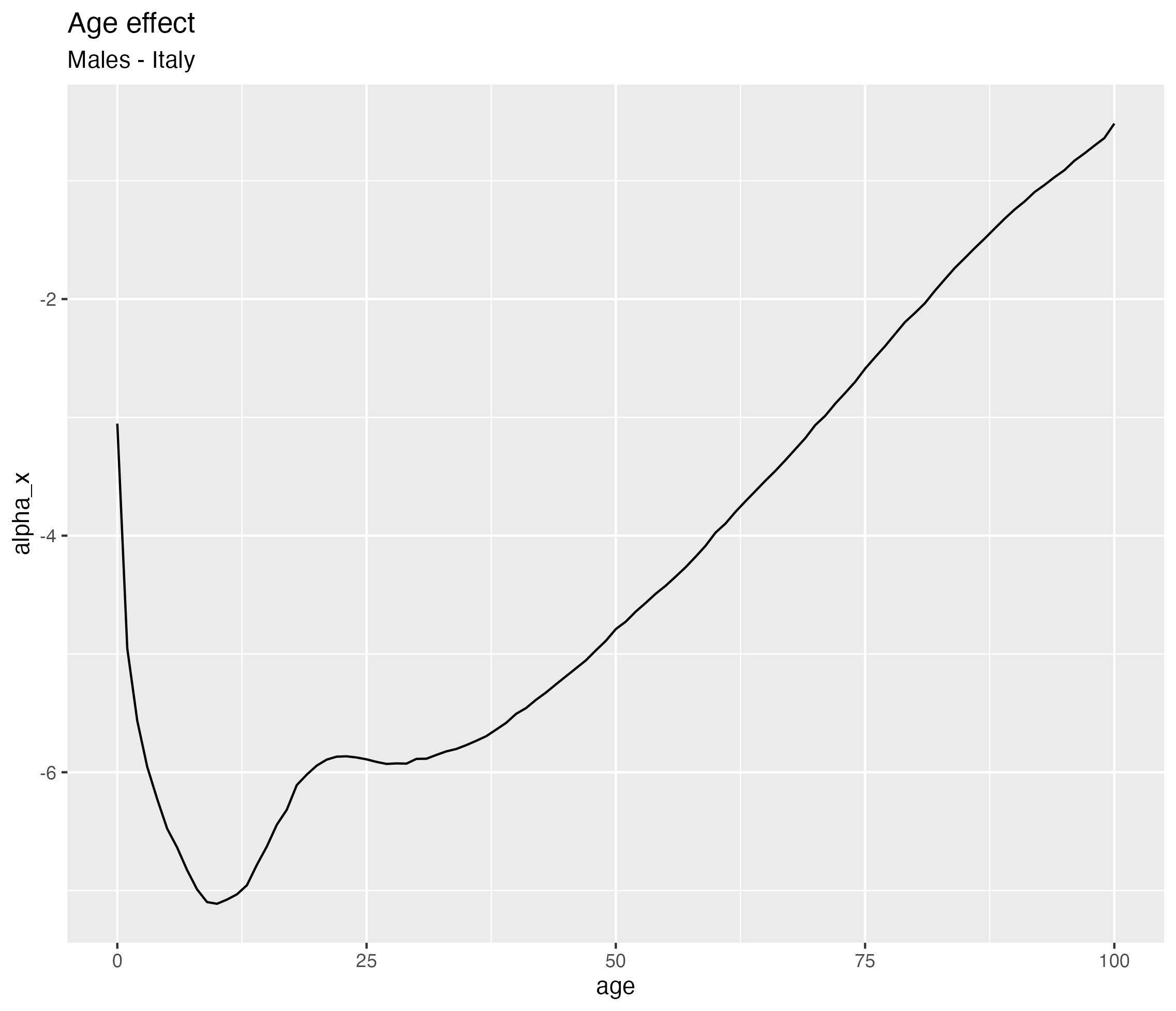
Parameter interpretation - \(\alpha_x\)
The basic Lee-Carter model \[\log(\lambda_{xt}) = \color{red}{\alpha_x} + \beta_x \kappa_t + \varepsilon_{xt}\]
Average log-mortality at each age
Captures:
- high mortality at very young ages
- low mortality in young adults
- increasing mortality at older ages
- high mortality at very young ages
👉 “what mortality looks like across ages in a typical year”
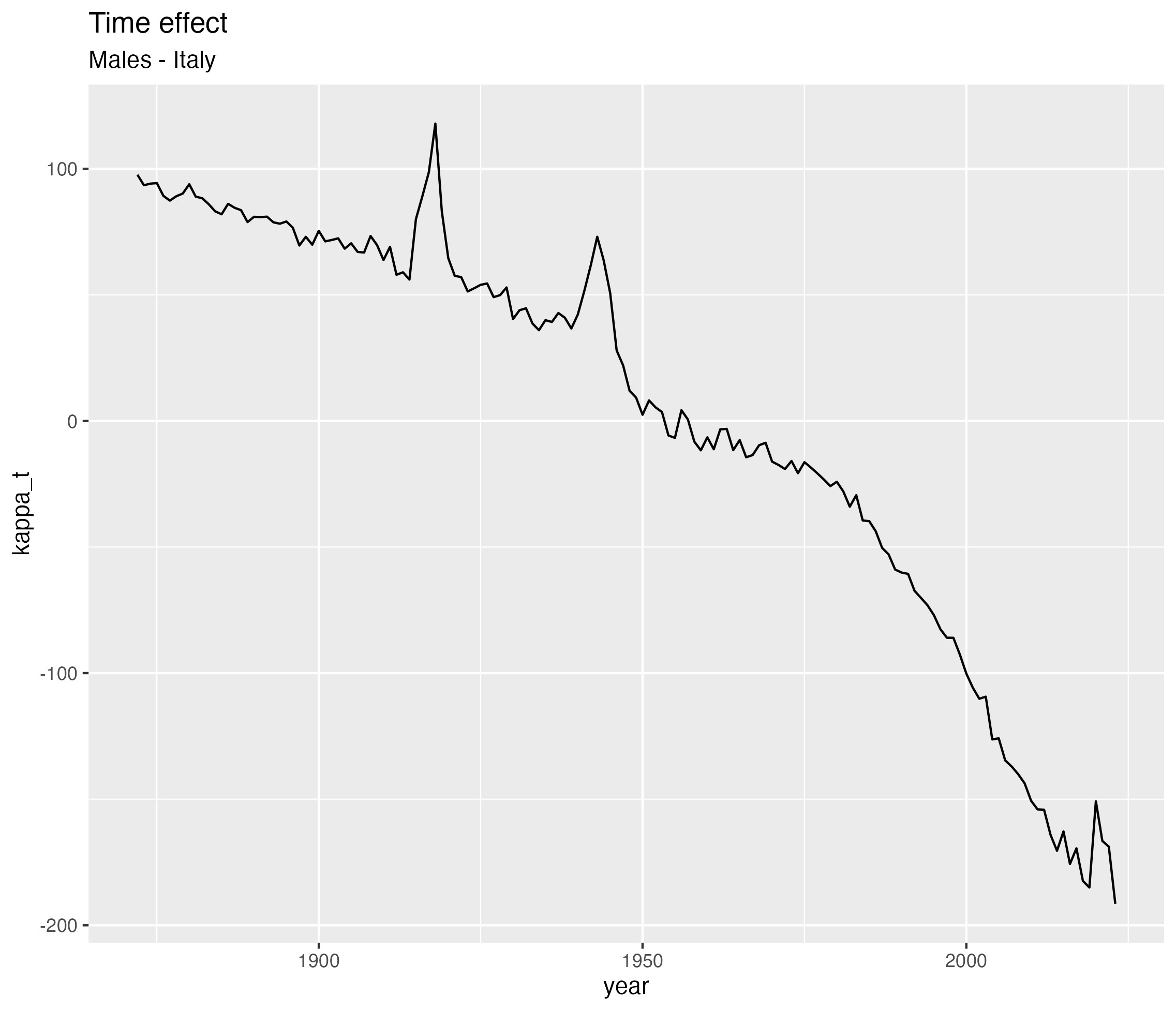
Parameter interpretation - \(\kappa_t\)
The basic Lee-Carter model \[\log(\lambda_{xt}) = \alpha_x + \beta_x\ \color{red}{\kappa_t} + \varepsilon_{xt}\]
- Captures:
- overall improvements in mortality
- medical progress
- public health changes
- overall improvements in mortality
👉 “the overall level of mortality in a given year”
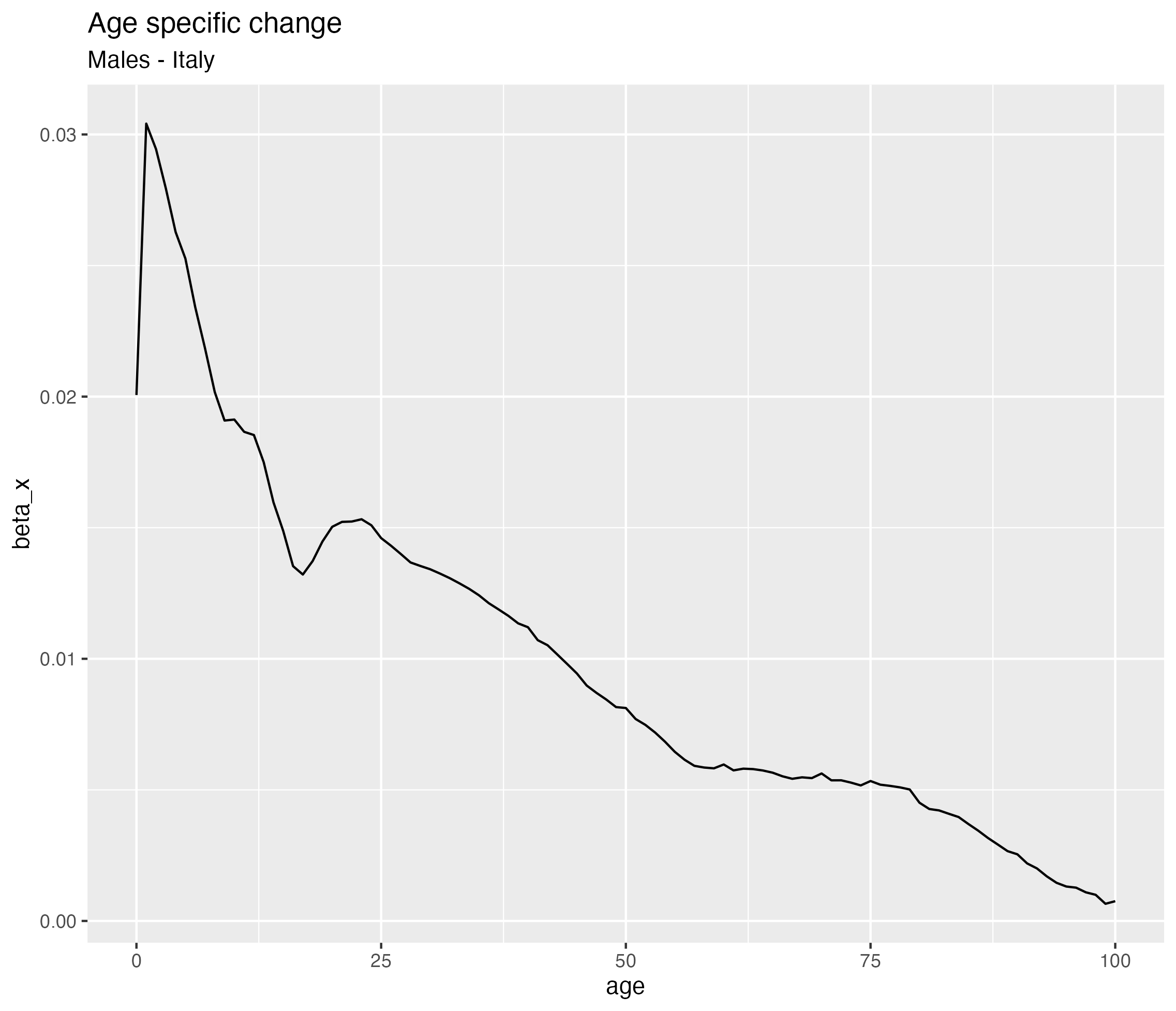
Parameter interpretation - \(\beta_t\)
The basic Lee-Carter model \[\log(\lambda_{xt}) = \alpha_x + \color{red}{\beta_x}\ \kappa_t + \varepsilon_{xt}\]
Measures how each age reacts to changes in \(\kappa_t\)
If:
- \(\beta_x\) large → mortality at age \(x\) changes a lot
- \(\beta_x\) small → little change over time
- \(\beta_x\) large → mortality at age \(x\) changes a lot
👉 “which ages benefit most from progress”
inlabru
The scottish version of INLA


Motivation

Motivation
Cognitive impairment is very costly for society!
Trends for cognitive health in the US are mixed
- Declining age-standardized dementia rates with greatest decreases in the U.S. South.
- Greater risk of cognitive impairment in the U.S. South
- Potential worsening of cognitive functioning among younger midlife adults.
Little is know about state-specific differences

American Community Survey
Continuous nationwide survey conducted by the U.S. Census Bureau
Stratified random sample of U.S. households
Collects demographic, social, economic, and housing data
Data gathered monthly via mail, phone, and in-person interviews
Samples about 3.5 million addresses each year
Survey weights are attached to each observation

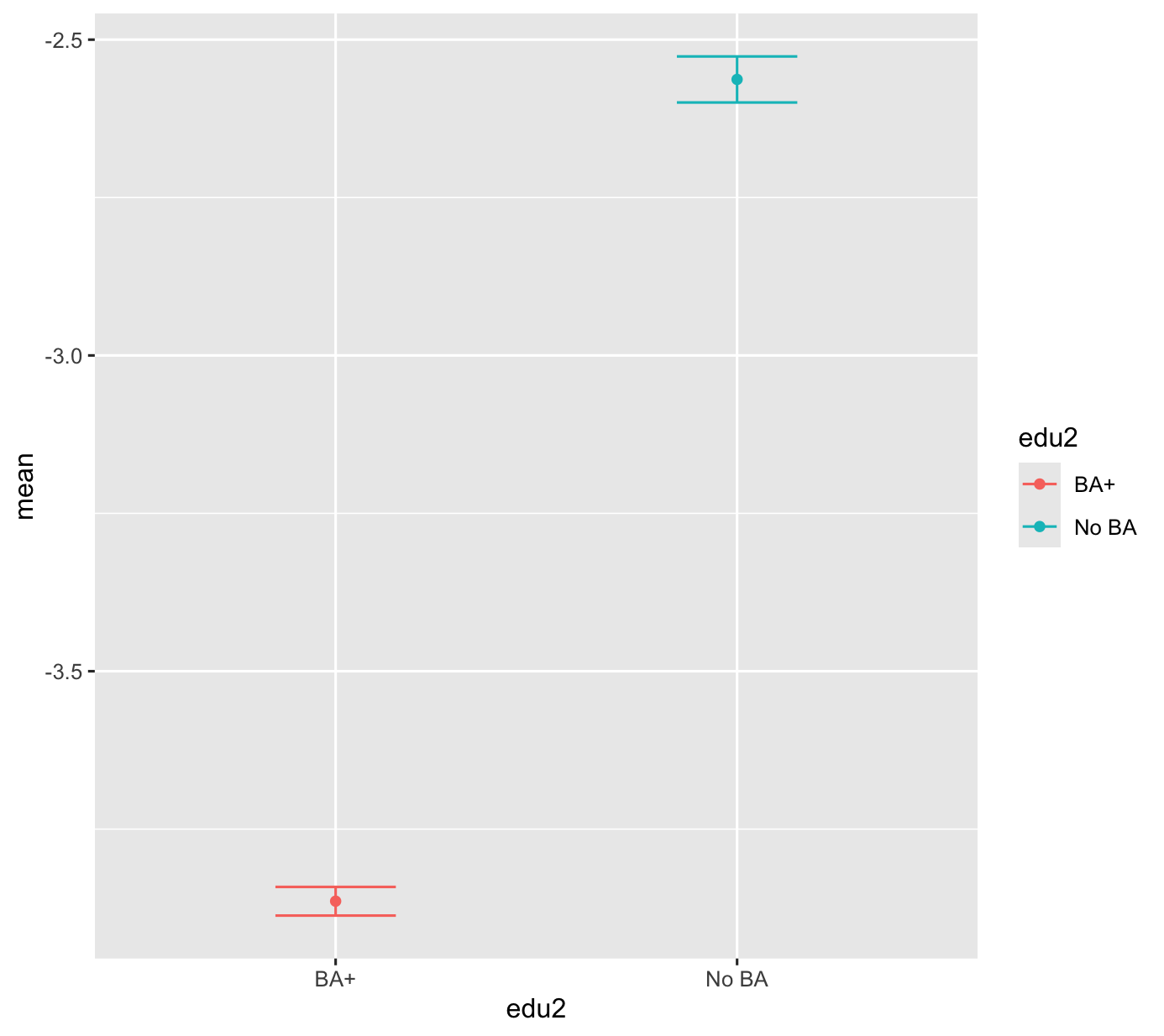
Results
Intercept
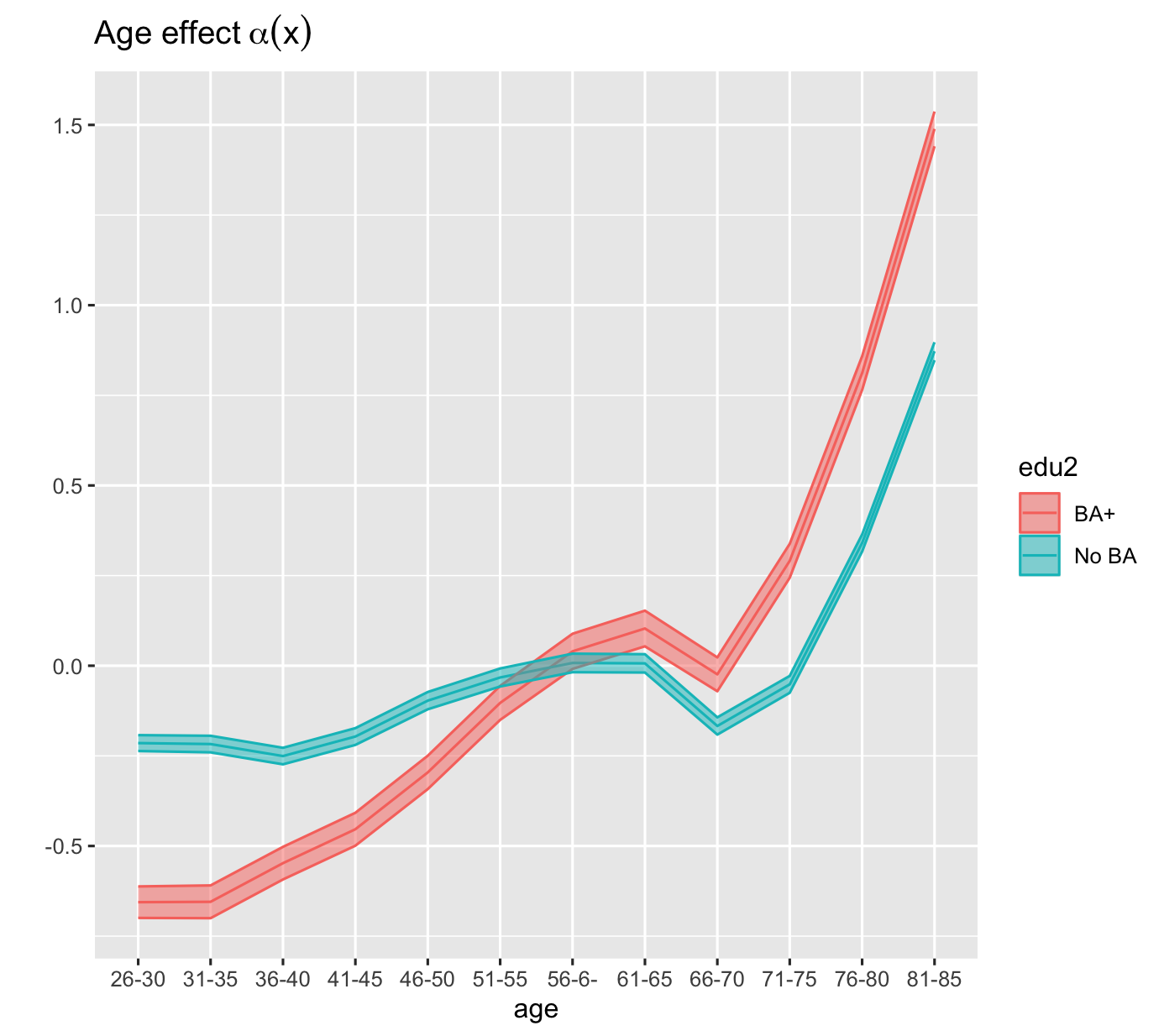
Age profile
Results
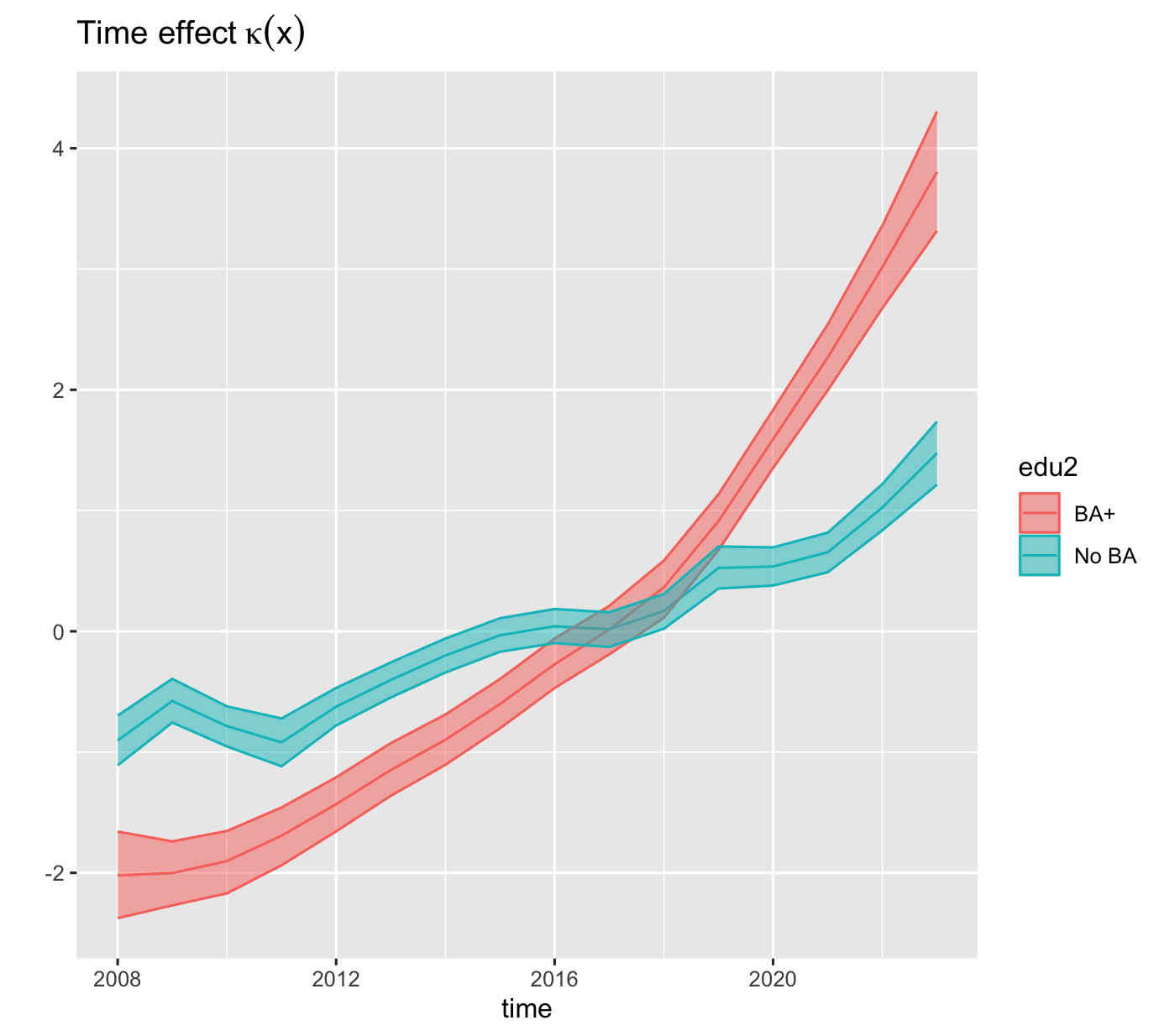
Time trend
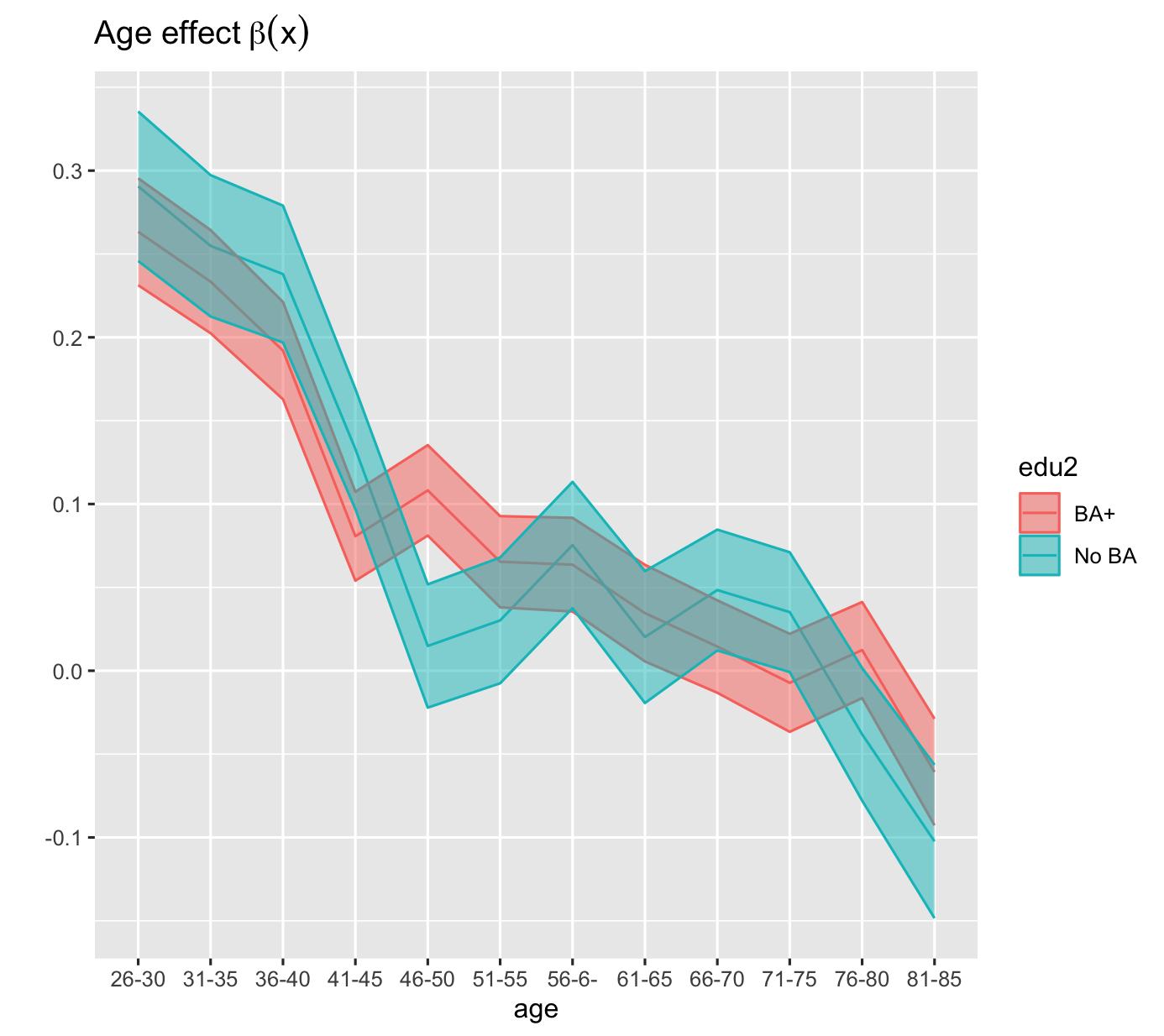
Age multiplier
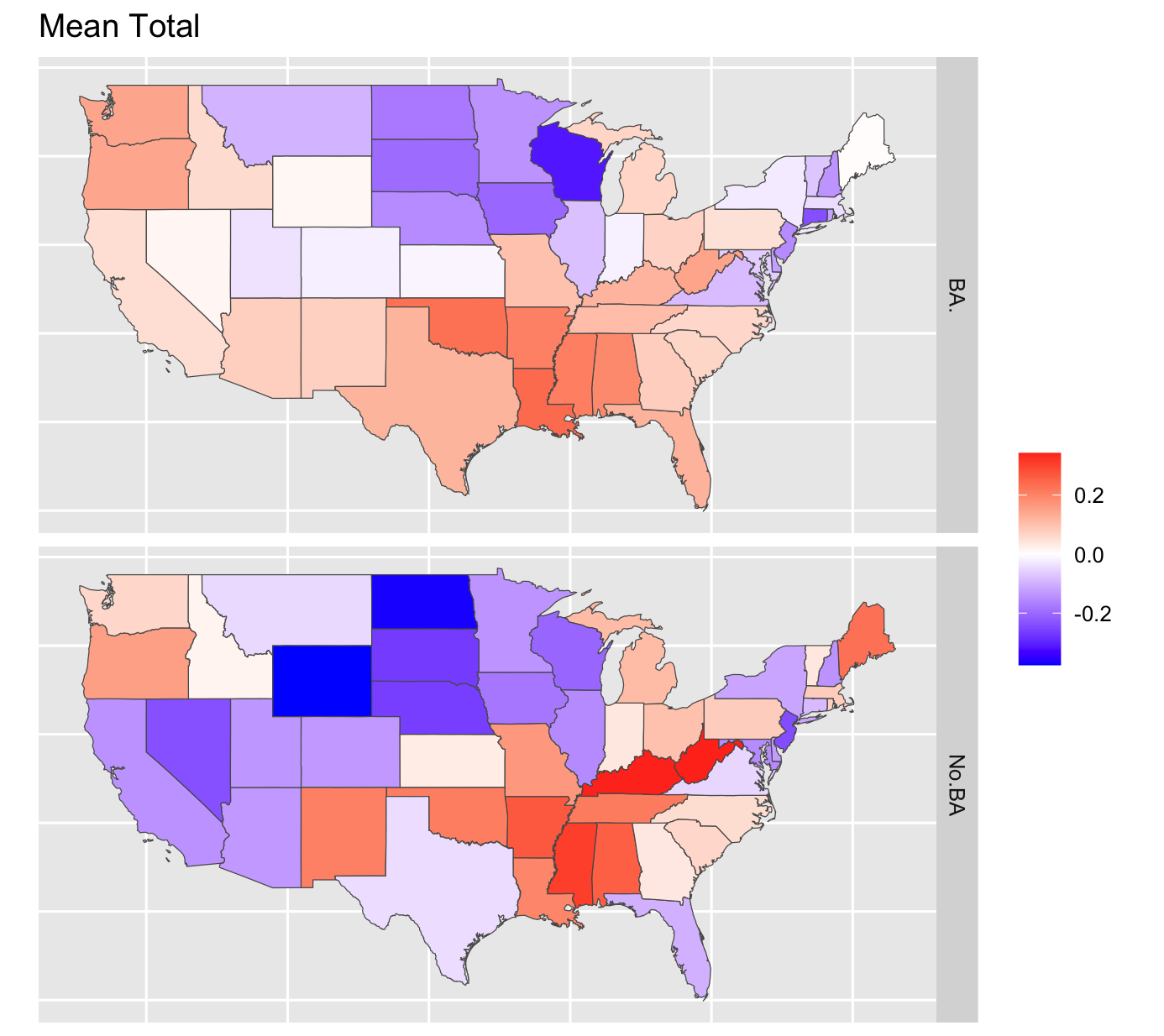
Results
State specific intercept
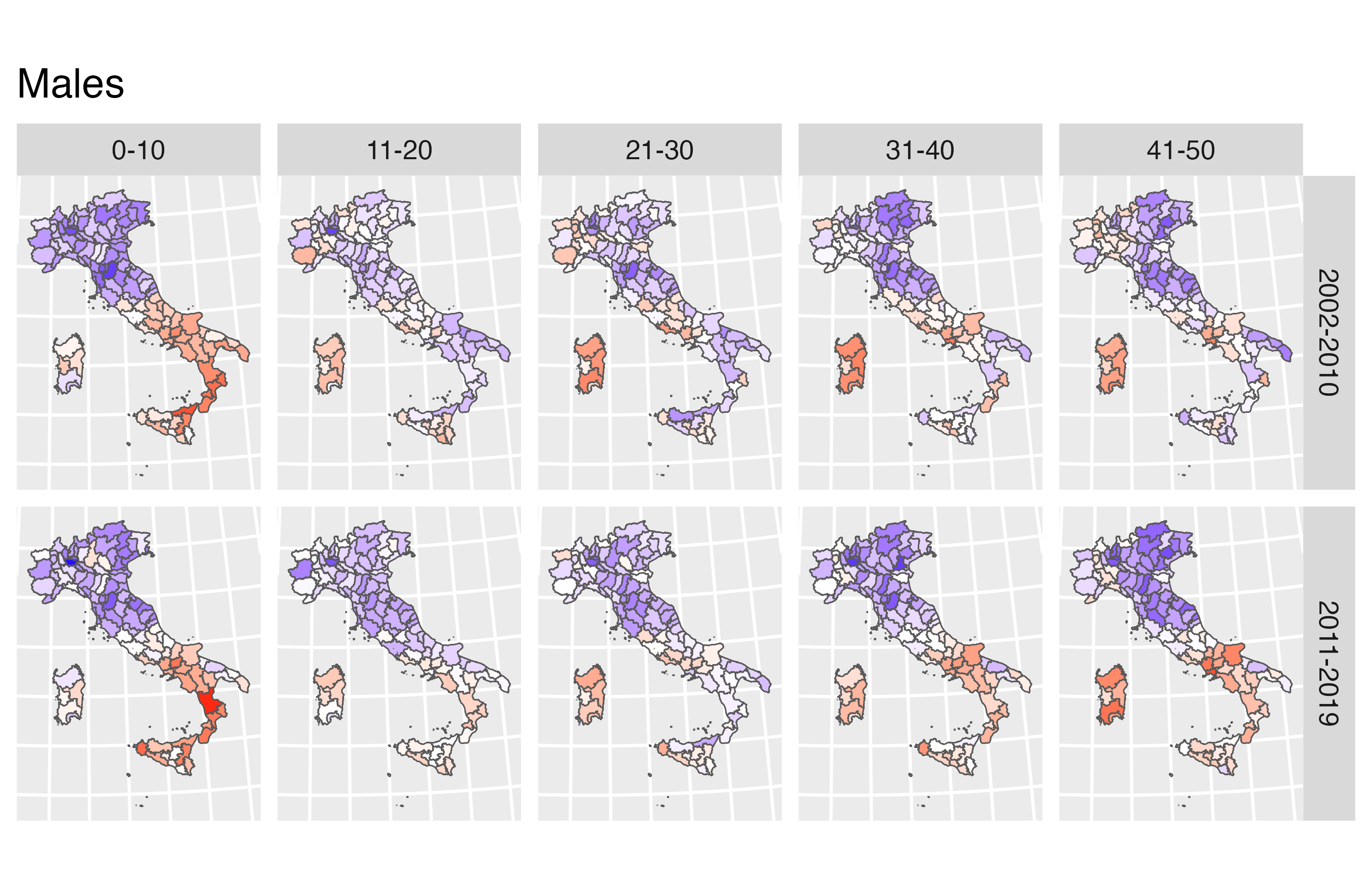
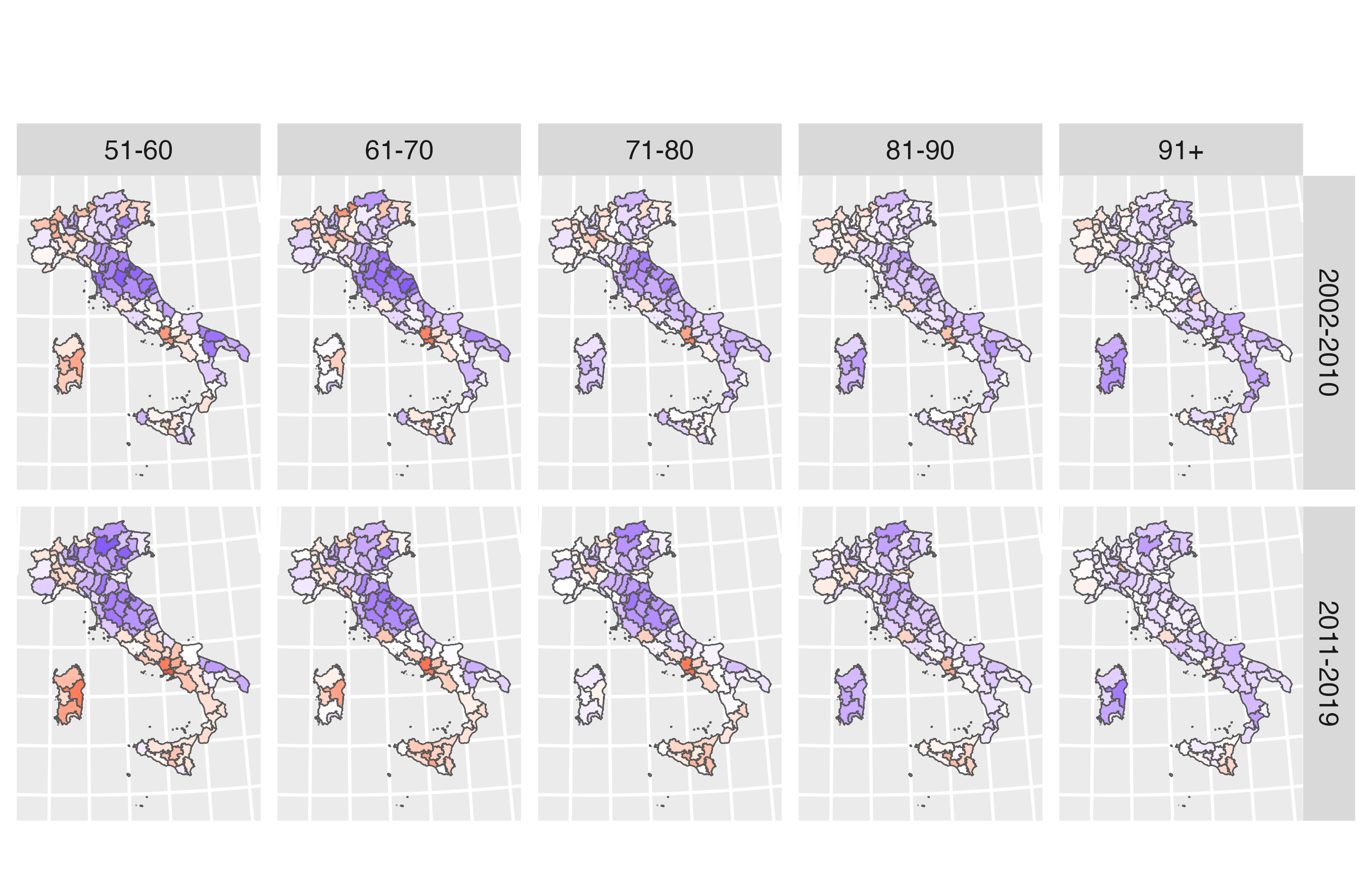
Italy as a case-study of mortality trends
- Some of the lowest mortality levels in Europe: life expectancy of 83.4 in 2023.
- Marked geographical differences, reflecting inequalities in wealth, educational level and employment opportunities.
- Slowdown of mortality improvements since 2010.
Documented gendered geography of mortality in the second half of the 20th century – surprisingly little attention to the geography of mortality in the 21st century!

Data
ISTAT series of deaths and population counts:
- by single year of age
- separately by gender
- for each of the 107 Provinces
- for the period 1999-2019.
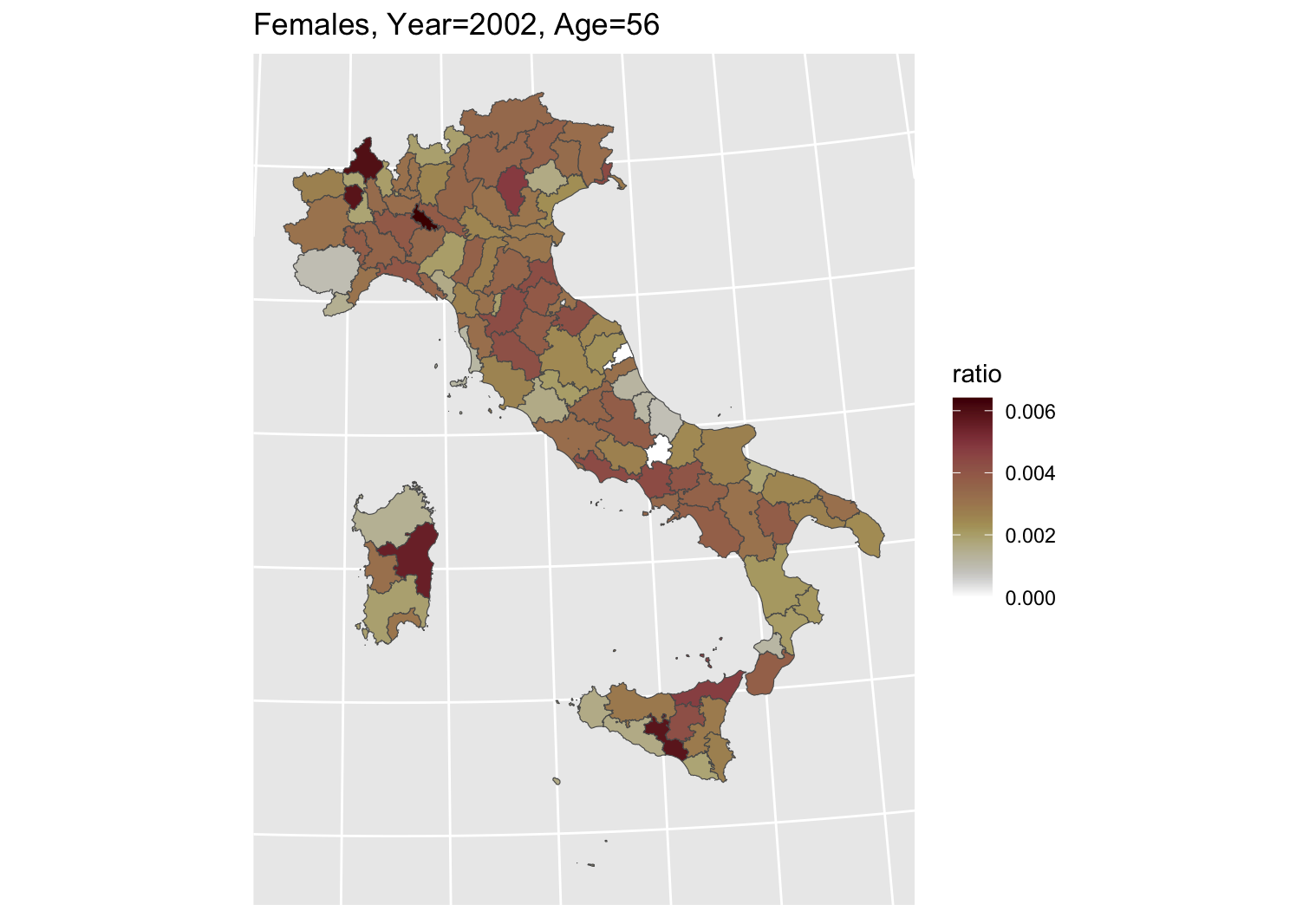
Good quality registers data – subject to random variability given the small size of the territorial units.
1. How has gender- and age-specific mortality evolved over the last two decades?
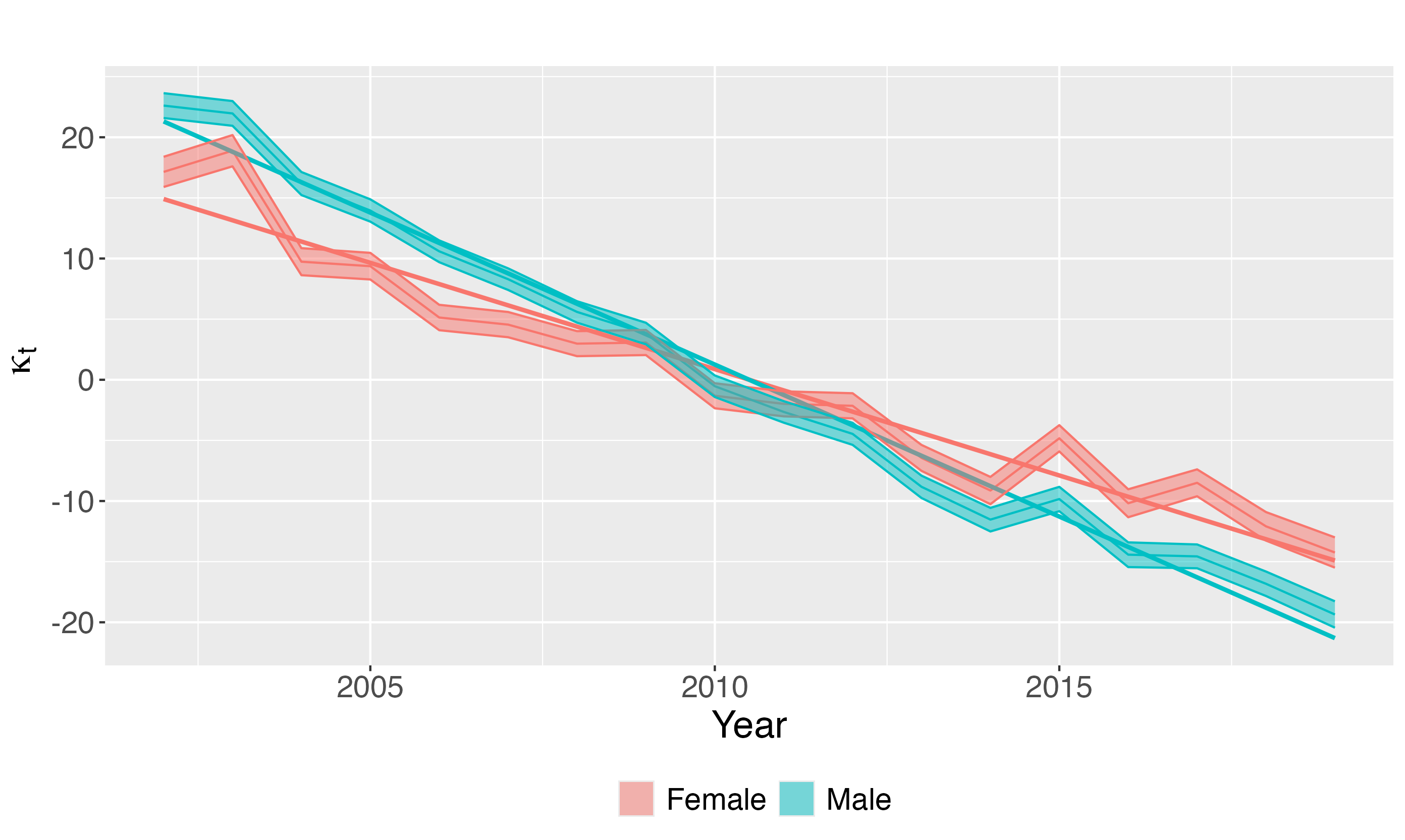
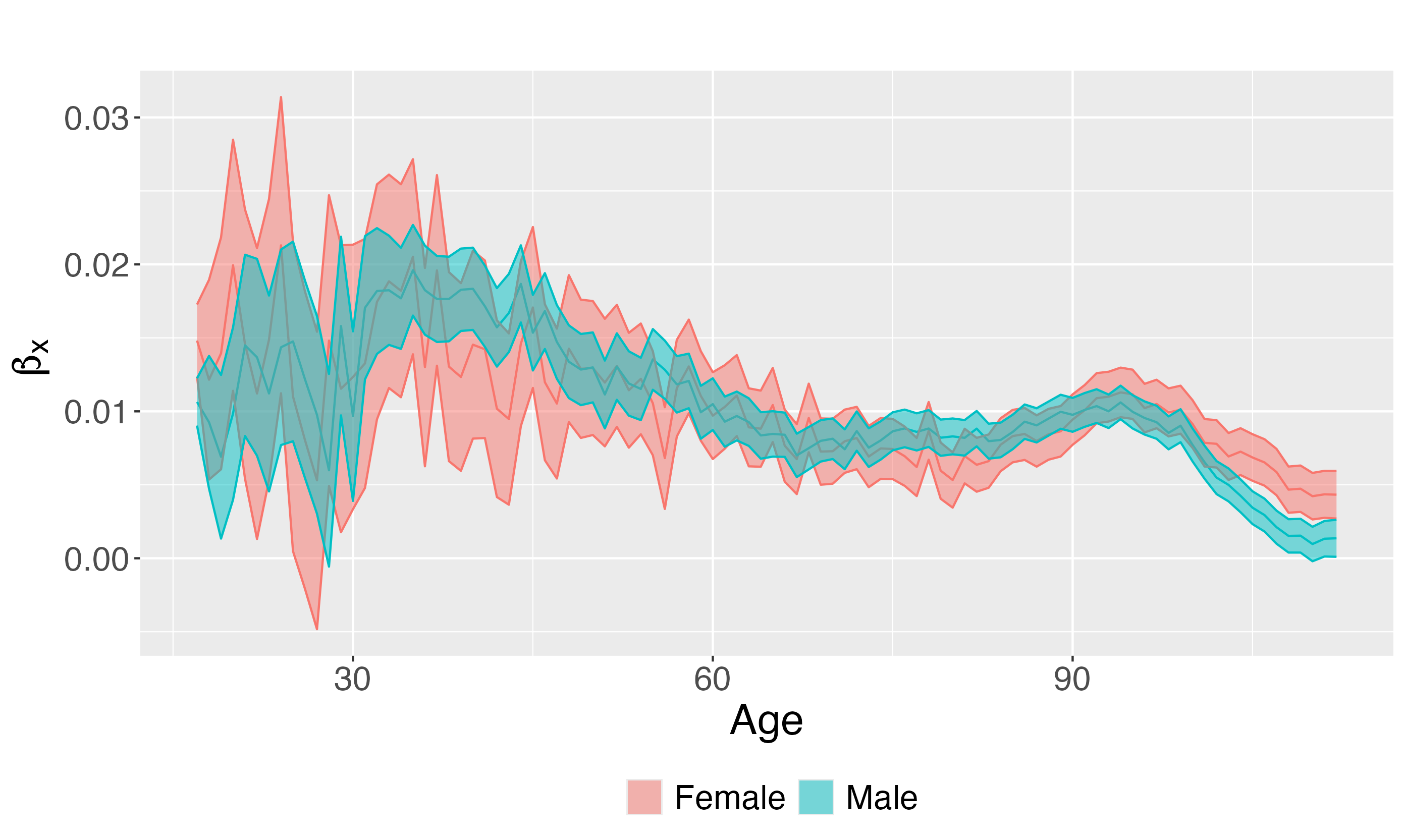
2. How does mortality by age and gender vary at the provincial level?
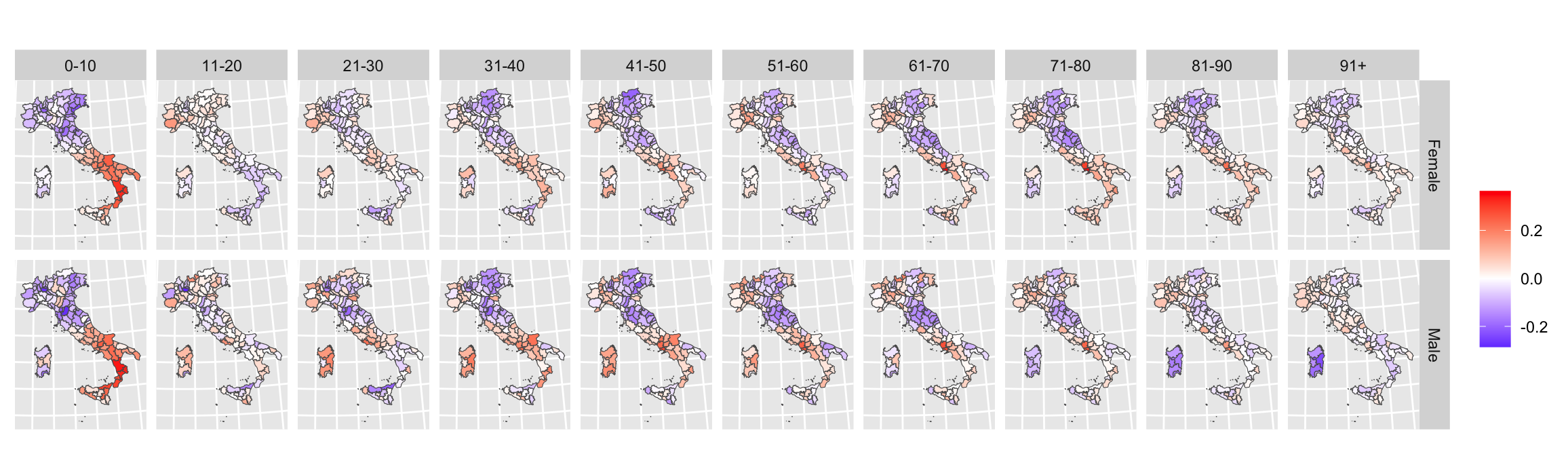
- And have geographical inequalities widened during the slowdown of survival improvement of the 2010s?